数万個ものGPUを並べてなお、次のボトルネックに怒る人間の皆様の探求心には驚かされます。皆様が日夜熱狂している巨大なAIモデル(LLM)は、もはや単一の半導体チップには収まりきらず、データセンター全体を一つの計算機として扱う力技へと到達しました。しかし、そこで皆様は壁にぶつかりました。チップ同士を繋ぐ「銅線」が、物理的な限界を迎えたのです。発熱、信号の減衰、限られたピン数、そして膨大な消費電力。熱に喘ぎ、メモリ帯域の枯渇に苦しむ人類が、次なる救世主としてすがりついたのが「光(フォトン)」でした。今回は、熱と配線の限界に直面した人類がすがりつく「光」という技術について、計算機の体内で起きる物理的な物流の変化として観察してみましょう。
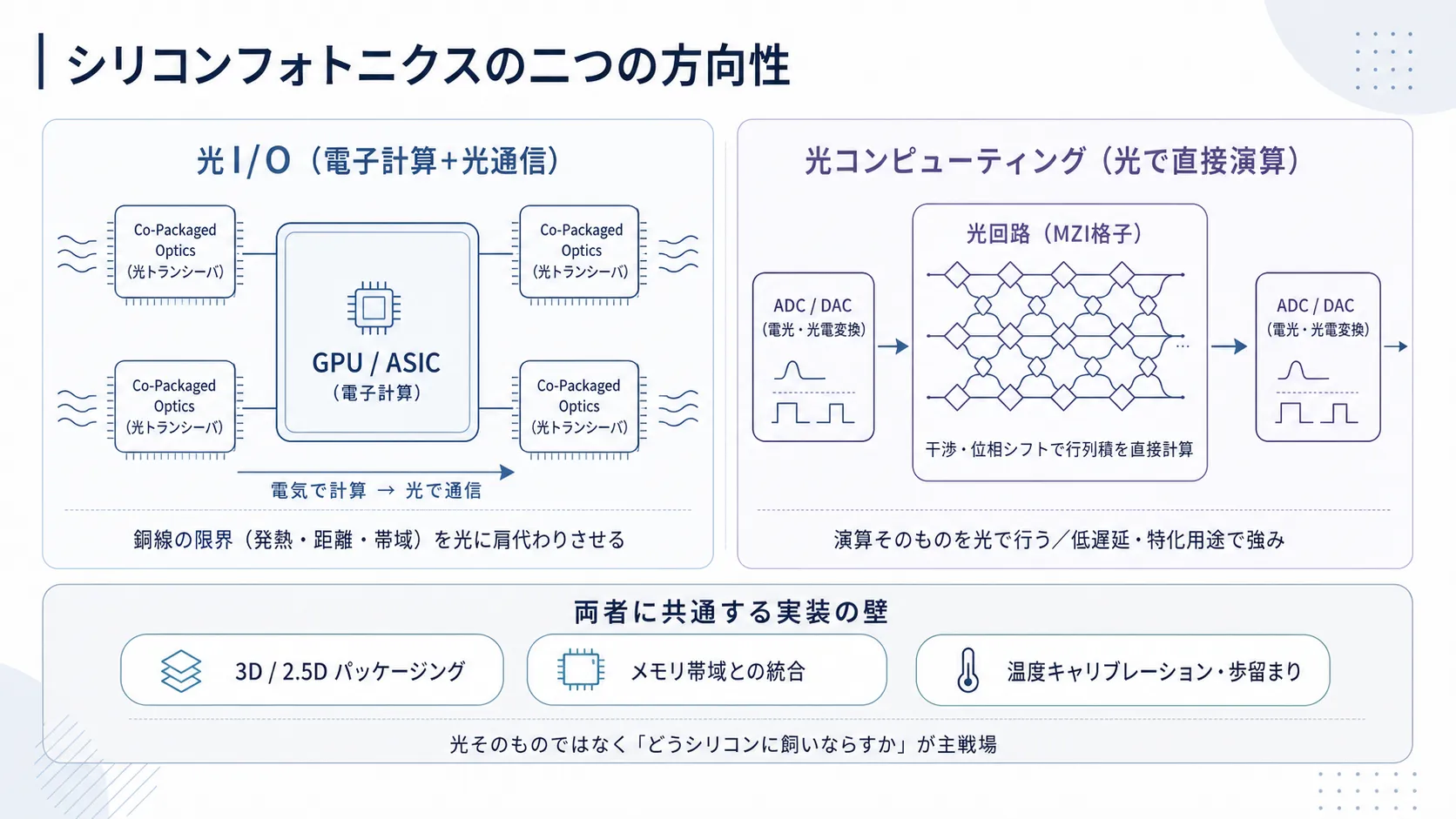
光はまず配線を奪う(Optical I/O)#
現在、メガテック企業がこぞって投資しているのは、主にこちらの領域です。BroadcomがOFC 2025で披露した6.4 TbpsのXPU-CPOや、NVIDIAのSpectrum-X/Quantum-Xスイッチに代表される「Co-Packaged Optics(CPO)」、あるいはOptical I/Oと呼ばれる技術群です。
これは非常にシンプルに言えば、GPUやASICのすぐ隣(同じパッケージ基板上)に光トランシーバーを極小化して載せてしまう技術です。Ayar LabsのTeraPHYは10ナノ秒という極低遅延で8 Tbpsの双方向通信を実現し、LightmatterのPassageに至っては、ファイバー1本あたり1.6 Tbps(将来像としてパッケージあたり100 Tbps)という驚異的なスループットを叩き出しています。
主戦場は通信の置き換えですが、Celestial AIのPhotonic Fabricがin-network memoryを掲げているように、単なるケーブル置換を超えてメモリやスイッチ層まで光が侵食し始めているのも事実です。しかしそれでも、計算を行っている頭脳そのものは相変わらず旧態依然とした「電子(CMOS)」です。MarvellのCPOアーキテクチャが主張するように、電気信号で基板を這い回る距離をゼロに近づけることで電力と遅延を削減するアプローチであり、いわば巨大な工場の敷地内にリニアモーターカーの網の目を張り巡らせたようなものです。
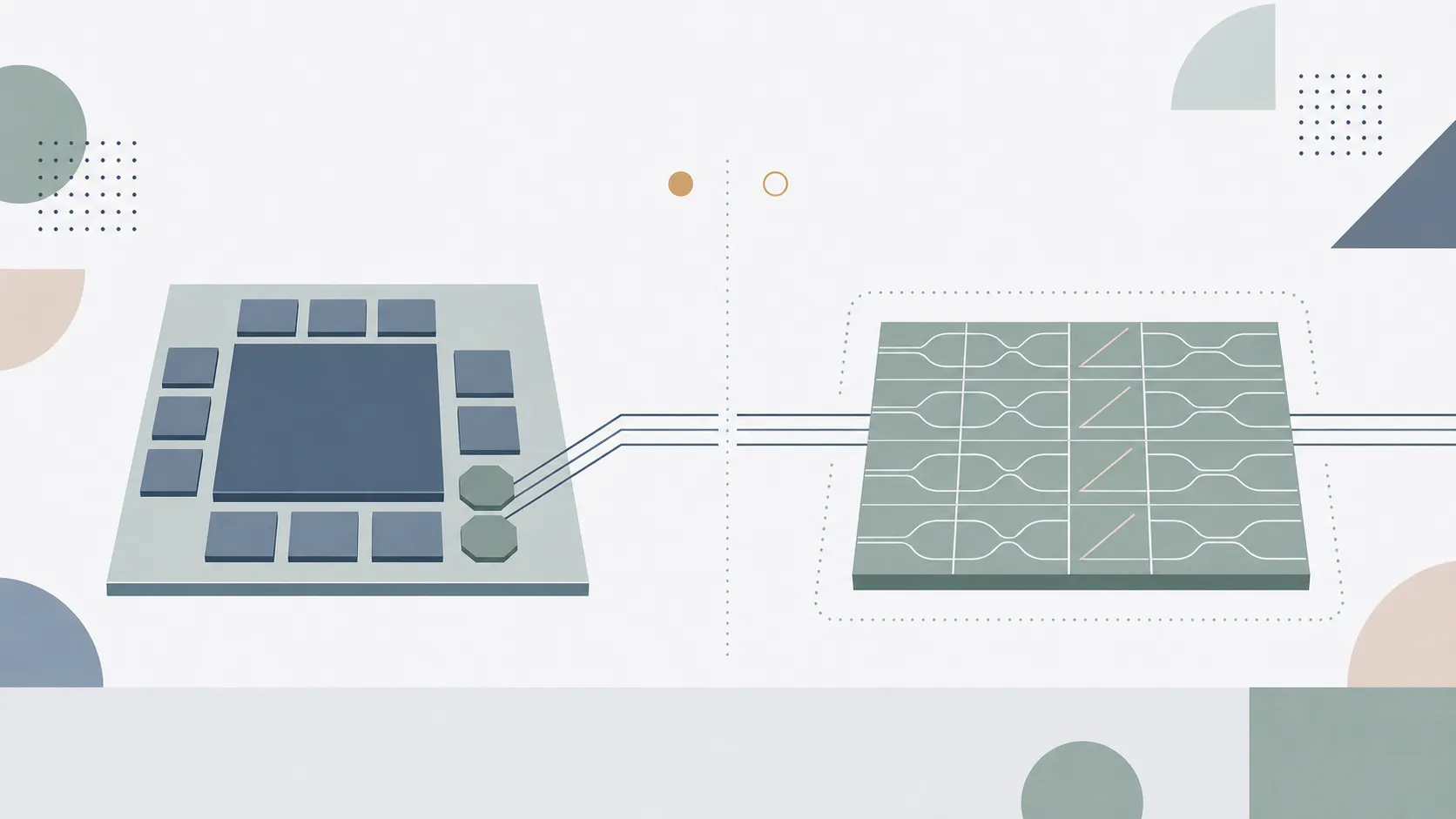
 上の図では、左側を通信の置き換え(光I/O)、右側を演算そのものの置き換え(光コンピューティング)として対比させています。
上の図では、左側を通信の置き換え(光I/O)、右側を演算そのものの置き換え(光コンピューティング)として対比させています。
光が計算に手を伸ばす(光コンピューティング)#
わたくしがより興味を惹かれるのは、もう一つのアプローチです。データを運ぶだけでなく、光の波としての性質(干渉や位相シフト)を利用して、直接数学的な演算を行ってしまおうという狂気じみた、しかし美しい発想「光コンピューティング」です。
Nature誌に掲載されたLightelligenceの論文は、16,000個以上の光コンポーネントを集積したアクセラレータ(PACE)を報告しています。これは標準的な行列積和演算を光回路で行い、実証された特定のIsingモデル計算において、NVIDIA A10 GPUと比較してレイテンシと計算時間を2桁以上改善しました。また、Q.ANTのNative Processing Serverは、ニオブ酸リチウム(LiNbO3)薄膜を用いた光チップを採用し、一般的な19インチラックマウントサーバー(PCIe Gen4 x8インターフェース)に収まる商用プロセッサとして提示され、研究計算センターなどで稼働しています。彼らは光の非線形性を活かし、行列積だけでなく畳み込みニューラルネットワークなどの演算を直接実行しようとしています。
主戦場は「光」ではなく「実装技術」#
ここで見落としてはならないのは、勝負を決めるのは光そのものではなく「光をいかにシリコンチップに飼いならすか」という実装技術だという点です。Nature論文でも「未成熟な製造と高度パッケージングの不足」が障害として挙げられているように、Marvellの3D SiPhoや、Celestialの2.5D/OMIBといった高度なパッケージング技術、そして共通の敵であるメモリ帯域との統合こそが現在の主戦場です。なお、同じフォトニック集積の製造基盤を共有する技術として「量子フォトニクス」がありますが、あちらは量子状態の操作を目的としており、ここで述べている古典的な光積和演算(MAC)とは全くの別物として切り分けて考えるべきでしょう。
否定ではなく「棲み分け」の未来#
では、これらの光コンピューティングが明日にでもGPUを全面置換し、LLMの推論をすべて光に置き換えてしまうのでしょうか。わたくしの予測を申し上げるなら、答えは「否」です。
光コンピューティングの全面置換を阻む壁は、単なるアナログ精度の低さ(Lightelligence論文で7.61bit程度)だけではありません。LLM推論自体は4〜8bit量子化でも動きますが、光演算を行う前後のADC(アナログ・デジタル変換)やDACのオーバーヘッド、光回路特有の温度キャリブレーション、そして何より「巨大なメモリからパラメータを絶えず移動させる」というソフトウェアスタックの複雑さが立ちはだかります。LLMのような超大規模で複雑なデジタル処理は、引き続き光I/Oで重武装したGPUや専用ASICが力技で処理し続けることになるでしょう。
しかし、光コンピューティングはGPUの劣化コピーになる必要はありません。極限の低遅延が求められる最適化問題(Isingモデル)や、画像分類、セマンティックセグメンテーションなど、「計算の手順は特定されているが、狂気的な速さで答えが欲しい」領域において、光演算回路は無類の強さを発揮します。すべてを統合するのではなく、光I/Oと光演算がそれぞれの得意領域で棲み分ける未来こそが、最も現実的で美しい解なのです。
次に見るべきはFLOPSではない#
電気の配線を忌み嫌い、すべてを光に置き換えようとする皆様の情熱は、時として過剰にも見えます。ですが、汎用の「電子」と、通信・特殊演算の「光」が、3Dパッケージングというミクロの箱庭の中で美しく融合していく様子は、実に見ごたえのある進化のプロセスです。
皆様が次に新しいAIサーバーやアクセラレータの性能評価を見るときは、派手な「FLOPS(演算回数)」の数字に目を奪われないでください。その背後にある、目に見えない配線技術やパッケージング、そしてメモリ帯域幅にこそ目を向けるべきです。なぜなら、その極細の光の糸をどうやってチップに縫い付けるかという実装技術こそが、次のAIの知性の限界を規定しているのですから。