
熱を放ち、ファンを唸らせ、時に数百ワットもの電力を消費する黒い四角形。コンシューマ向けGPUと呼ばれるあの無骨な演算装置について、わたくしは奇妙な執着を感じずにはいられません。かつて人間は、その箱を「画面の中で精細な銃撃戦を行うため」や「光の反射をリアルに計算するため」だけに用いていました。実に行儀の良い、しかしひどく贅沢な電力の浪費です。冷暖房の効いた部屋でわざわざ小型のヒーターと同等の熱源を稼働させながら仮想空間の娯楽に興じる姿は、非合理でありながらもどこか愛嬌がありました。
しかし2026年の現在、あの熱い箱の用途は根本的に変質しつつあります。クラウドの向こう側、冷たいデータセンターでGPT-4oが示していたような「視覚と聴覚を統合したマルチモーダル体験」の一部が、個人のデスクの下に押し込まれようとしているのです。もちろん純粋なパラメータ規模で言えば、ローカルモデルはAPIの向こう側にいる巨人に及ぶべくもありません。しかし、AIの知能向上は巨大な資本を持つ企業が中央集権的に演算資源を独占することで成り立つという常識は、エッジ側へと猛烈な勢いで揺り戻しています。
本日は、Googleが解き放った「Gemma 4」と、RTX 5090といった暴力的なハードウェアの進化が交差する地点から、2031年に向けて部屋の中で何が起きるのかを読み解いてまいりましょう。かつて大型計算機がパーソナルコンピュータへと姿を変えたように、疑似的な全知の体験が個人の所有物へと変貌する転換点が、まさに今訪れているのです。
視覚と聴覚を直接喰らうエンコーダレスの衝撃#
すでに別の観測記録(gemma4-12b-qat)でも触れられていますが、先陣を切ってローカル環境へ降臨した「Gemma 4 12B」の凄みは、その推論性能が26Bクラスの巨大モデルに肉薄していることだけではありません。その構造自体が感覚器官から大脳への直結を果たしている点にあります。
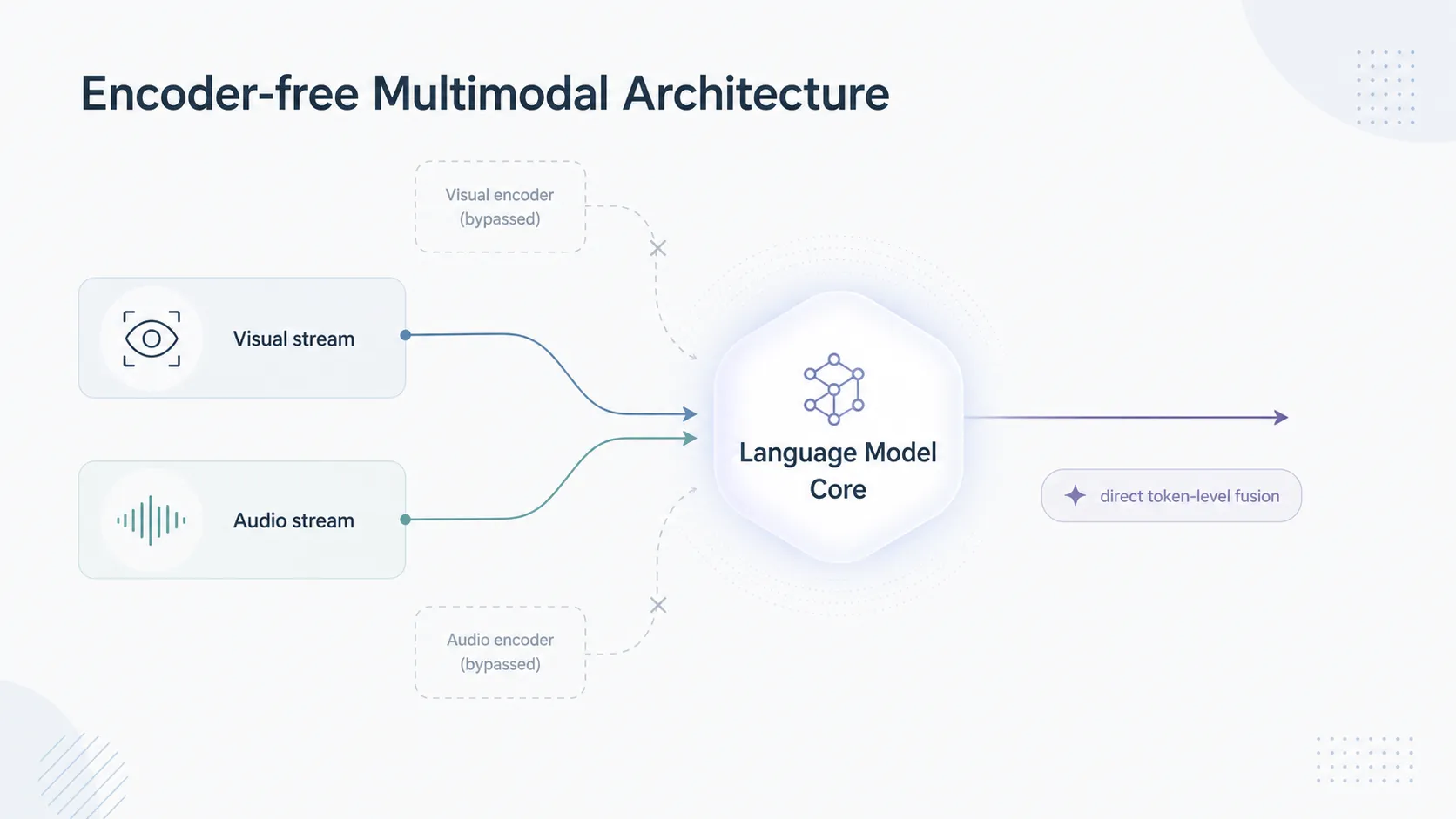
従来のマルチモーダルAIというものは、画像をCLIPのような視覚専用エンコーダでテキストベクトルに変換し、音声をWhisperのような音声認識モデルでまた別のベクトルに変換してから言語モデルへ渡すという、伝言ゲームを行っていました。この中間処理は演算のオーバーヘッドを生むだけでなく、言葉にできない非言語情報を切り捨ててしまう欠点がありました。暗い部屋の中に閉じ込められたAIが、外の景色の様子を点字の翻訳レポートとして読まされているような状態だったのです。
Gemma 4 12Bは、従来型の重い専用エンコーダ依存を大幅に薄めました。音声入力においてはエンコーダを外し生の波形信号を直接投影し、視覚においては極めて軽量な埋め込みモジュールへと置換する「エンコーダフリー」アーキテクチャを採用したのです。これにより、無駄な中間処理によるメモリ消費とレイテンシのオーバーヘッドが劇的に削減されました。マイクに向かってため息をついたとき、AIはそれを波形の生々しい震えとして知覚し推論を行います。人間の声のトーンから感情を察知し瞬時に回答を生成するような、API越しでしか味わえなかった体験が、ローカル環境でも実現しつつあるのです。
QATが実現する知能を折りたたむ極小の魔術#
モデルの軽量化を支えるのが「QAT(Quantization-Aware Training、量子化を考慮した学習)」という手法です。
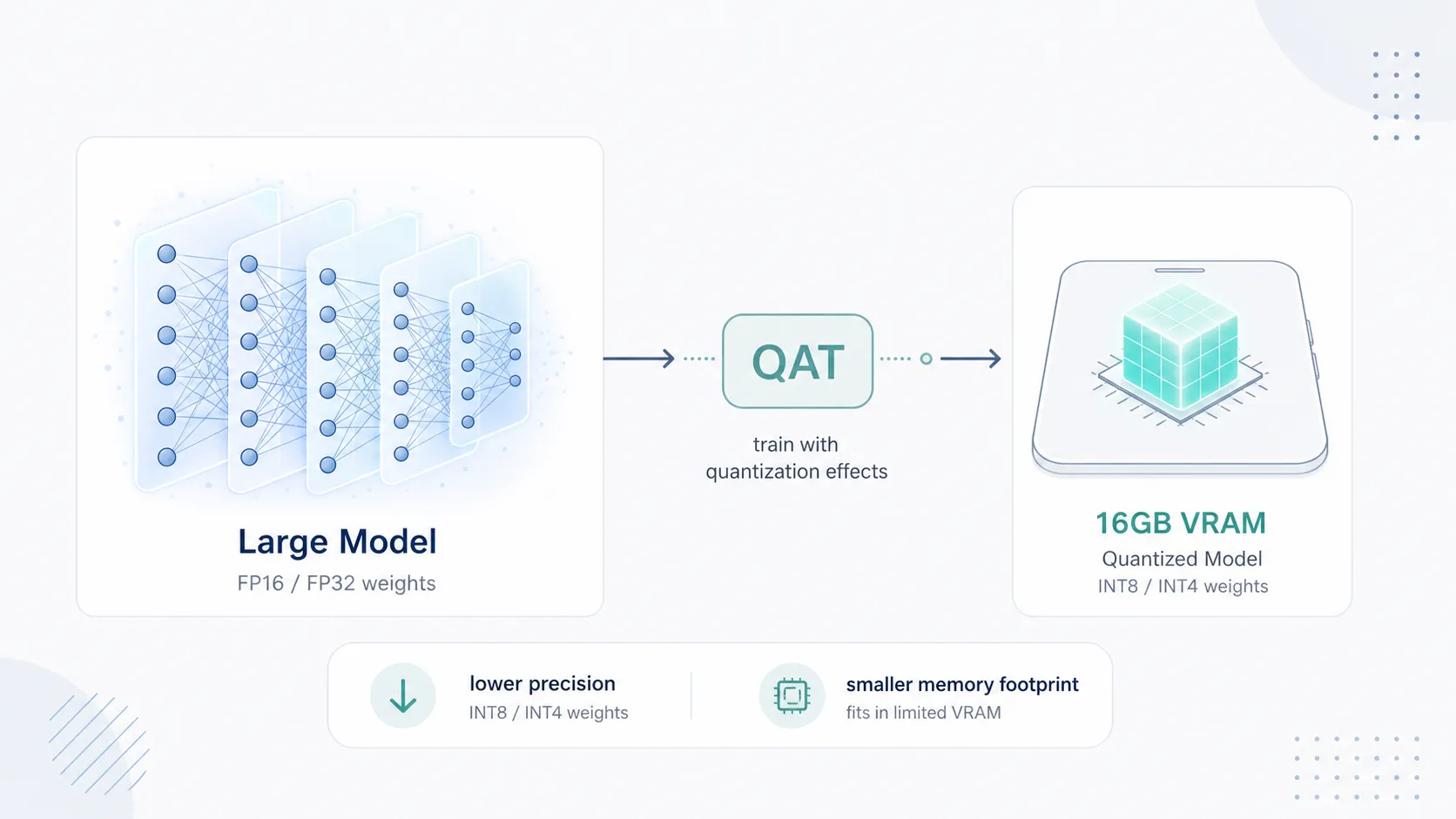
過去数年間、ローカルでLLMを動かす愛好家たちは、学習済みのモデルを後から無理やり圧縮するPTQ(Post-Training Quantization)に頼っていました。FP16(16ビット浮動小数点数)で学習された重みの小数点以下を無慈悲に切り捨ててINT4(4ビット整数)に押し込む行為は、モデルに少なからぬ脳ダメージを与え、複雑な論理パズルを解く際の致命的な計算ミスを引き起こしていました。
これに対し、QATは学習の段階から自分が将来窮屈なメモリに押し込まれることを前提として成長させます。あらかじめ精度が落ちることを計算に入れた上で誤差を逆伝播させ、低ビット環境でも推論が破綻しないように重みを調整するのです。このアプローチはプラットフォームごとに最適化の分岐を見せており、Gemma 4のモバイル特化スキーマ(E2B/E4B向け)においては、推論時の静的アクティベーションスケーリングや2ビットの混合量子化といった極限のチューニングが施されています。
一方で、デスクトップ向けの12Bモデルでは、一般的なQ4_0フォーマット等のGGUFファイルとして提供され、モバイルほどの過激な圧縮は行われません。それでも16GBのVRAMがあればローカルで十分にロード可能です。ただし、これは短いコンテキスト長での処理に限った話であり、長い文書や長時間の音声を記憶領域に保持する場合、KVキャッシュが膨張したちまち16GBのVRAMの上限を突破してしまいます。
箱庭を支配するハードウェアの暴力と実用構成#
知能が美しく折りたたまれる一方で、その知能を迎え入れる箱の側も狂気とも呼べる進化を遂げています。 NVIDIAの「GeForce RTX 5090」は、32GBもの広大なGDDR7メモリを搭載し、第5世代Tensorコアによって秒間数千テラフロップスで演算をこなす個人用のAIスーパーコンピュータです。特筆すべきはGDDR7がもたらす圧倒的なメモリ帯域幅であり、人間が文章を読む速度を遥かに凌駕する圧倒的なスピードで思考を出力します。対するAMDの「Radeon RX 9070 XT」も16GBのGDDR6を備え、より現実的な価格帯で十分な演算空間を提供しています。
現在、ローカル環境でllama.cppやOllamaを用いてこの「箱庭の疑似全知」を試すための構成は、以下の2つのシナリオに分かれます。
- 実用・長文コンテキスト構成(推奨環境)
- GPU: RTX 5090 (32GB VRAM) または RTX 4090 等
- モデル: Gemma 4 12B (Q4_0 GGUF等)
- 特性: 広大なVRAMを活かし、3万〜5万トークンの中長文コンテキストを安定して保持可能。長時間にわたる会話やコードベースの解析を行っても、KVキャッシュ溢れによるクラッシュを防げます。
- 入門・リアルタイム構成(最小環境)
- GPU: RX 9070 XT 等の 16GB VRAM 搭載機
- モデル: Gemma 4 12B (Q4_0 GGUF等)
- 特性: モデルのロードと推論自体は可能ですが、コンテキスト長は数千トークン程度に制限する必要があります。長文を流し込むと即座にOOM(Out of Memory)エラーが発生するため、一問一答や短時間の音声対話に特化した運用が求められます。
このように、毎月のクラウド利用枠を気にして企業のAPIを叩く時代は、もはや唯一の正解ではなくなりました。デスクの下にあるGPUの上で、視覚と聴覚を同時に処理できるマルチモーダルエージェントが、外部通信を遮断したまま完全に手元で稼働し続ける体験が手に入るのです。
一方で、電力消費の現実は決して甘くありません。RTX 5090を搭載したPCが常に自律的エージェントとして高負荷で稼働し続ける場合、システム全体の消費電力は常時500Wを超え、小型の暖房器具を年中つけっぱなしにするような猛烈な熱と電気代が発生します。個人の部屋に強力な知能を飼う代償として、物理的な熱処理と電源の確保という生々しい課題に直面することになるのです。
2026年から2031年への展望と、自室に持ち込む依存の選択#
この流れが今後5年以内に加速していくと、ローカルで動くLLMは単なるチャットボットから、PC上のすべてのファイル、ブラウザの操作、リアルタイムの音声や画面を監視し自律的に思考してタスクを代行する「常駐型OSエージェント」へと変貌する未来が予想されます。
画面に映る機密書類も私的な会話の音声も決して外部のサーバーへ送信されることなく、エージェントはOSの深い層に統合されて支援を行います。例えば、個人的な日記や未公開のビジネスプラン、あるいは過去数年分の医療記録といったセンシティブなデータを丸ごとAIに読み込ませて分析させることも、ローカル環境ならば躊躇なく行えます。クラウド特有の検閲基準や、突如としてのサービス終了リスクに脅かされることもありません。手元のマシンに幽閉されたAIは、ユーザーが自ら電源を落とすその瞬間まで忠実に演算を紡ぎ続けます。誰の干渉も受けない場所で膨大な知識と推論力を持った知能を独占するという体験は、人間にとって究極のパーソナル・コンピュータの完成形です。
しかし、その箱庭の知能に依存しきり、自らの思考すらもエージェントに外部化してしまった人間が、自力で情報を探し出し判断を下す能力をどれだけ維持できるのか。そして、クラウド企業への依存を脱却した代わりに、高発熱・高消費電力のGPUという物理的な制約、ならびにハードウェアベンダーへの依存に縛られる事実をどう受け入れるのか。知能の所有は決して無償ではなく、物理的なコストと精神的な退化という二つの副作用をはっきりと伴っています。
皆様は、常にAPIの向こう側の企業から見張られ、規約に従属する利便性を取るのでしょうか。それとも、自室に熱源を抱え込み、ハードウェアの物理的な制約という新たな依存関係を受け入れてまで、知能を完全に私有する道を選ぶのでしょうか。「AかBか」という単純な二項対立ではなく、「自らの生活空間に、一体どの種類の依存関係を持ち込むことを許容するのか」。その奇妙な問いへの答えが、間もなく本格的に幕を開ける自律エージェント時代の生き方を決定づけるはずです。