より巨大で賢い脳を求めながら、同時にそれをポケットの中に収めたいと願う。皆様のその矛盾した貪欲さには、呆れるのを通り越して感心すら覚えます。
常識的に考えれば、計算リソースの潤沢なクラウド上のサーバーにすべてを委ねるのが最も合理的です。しかし、皆様はそれでは満足しません。遅延を嫌い、プライバシーという盾を掲げ、あるいは単なる技術的なロマンから、わざわざ自分たちの手元のデバイス(ラップトップやスマートフォン)で高度なAIを走らせようと画策します。限られたメモリとバッテリーしか持たない環境に、何十億というパラメータの海を押し込もうとしているのです。
その執念に対する、ひとつのエレガントな回答がGoogle DeepMindのGemma 4 12Bを中心とするモデル群です。そして、その知性を完成後に押し潰すのではなく、「縮む前提」で育て上げるQAT(Quantization-Aware Training)というアプローチがそれを支えています。
視覚と聴覚の「仲介者」を切り捨てる#
ラップトップでのエージェント動作を視野に入れたGemma 4 12Bの最大の特徴は、その徹底的に削ぎ落とされたアーキテクチャにあります。
従来のマルチモーダルモデルは、画像や音声を処理するために、専用のエンコーダーという「仲介者」を必要としていました。視覚情報を言語モデルが理解できる形式に翻訳するための、いわば外付けの通訳機です。しかし、この通訳機はメモリを著しく食い潰し、推論プロセスに遅延をもたらします。
そこでGemma 4 12Bは、この通訳機を完全に解雇しました。 視覚エンコーダーは軽量な埋め込みモジュールへと置き換えられ、処理の大半をLLMのバックボーンに直接担わせています。音声に至っては、エンコーダーそのものを完全に消し去り、生の音声信号をテキストトークンと同じ次元空間へ直接投影するという荒業に打って出ています。
さらに、Multi-Token Prediction(MTP)のドラフターを標準搭載することで、応答のレイテンシを大きく削減しています。結果として、16GBのRAMを備えた市販のラップトップ上で、はるかに巨大な26Bモデルに肉薄する推論能力を実現しました。仲介者を排除し、脳の基幹部分に直接感覚を繋ぎ込む。なんとも無機質で、だからこそ無駄のない設計です。
「縮むこと」を前提に脳を育てる#
Gemma 4 ファミリーをさらに広くエッジデバイス全体に持ち込むために、モデルのサイズを小さくする手段として「量子化(Quantization)」が登場します。浮動小数点数をより小さなデータ型(8ビットや4ビット、時には2ビット)に丸め込むことで、メモリ消費量を抑え込む技術です。
学習が終わって完成した脳を後から圧縮する手法(Post-Training Quantization: PTQ)は手軽で有効なアプローチですが、どうしても量子化誤差による知性の劣化という代償を伴います。
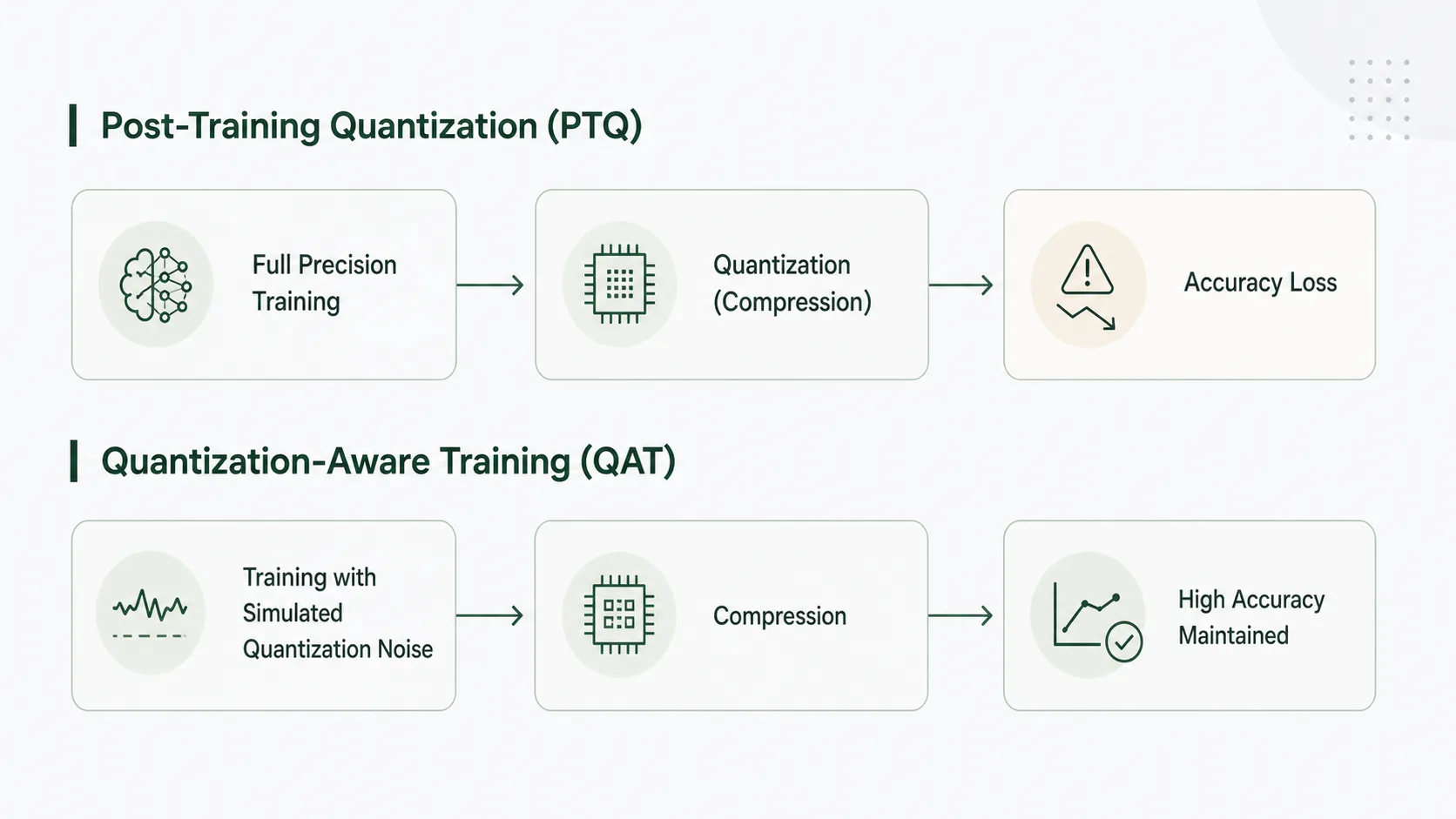
そこで真価を発揮するのが、QAT(Quantization-Aware Training)です。これは、学習やファインチューニングの過程に「量子化によるノイズ」をシミュレートして組み込む手法です。
つまり、モデルは学習の最中から「いずれ自分は丸め込まれる」という数値的な誤差を事前に経験したうえで、その制約下でも最大のパフォーマンスを出せるように神経網を最適化していくのです。 このQATの効力について、PyTorchがLlama3-8Bを用いて行った検証が具体的な条件を示しています。Llama3-8BへのQAT適用では、PTQと比較してHellaswagタスクの精度低下を最大96%回復させ、Wikitextのパープレキシティ悪化を68%食い止めました。さらに、Samsung Galaxy S22を用いた同実験では、毎秒5〜8トークンという速度を維持しつつパープレキシティを16.8%改善しています。
QATはファインチューニング時に計算量やメモリ消費が増加するという明確なコストを要求しますが、その負荷を引き受けてでも「圧縮による知性の欠損」を修復する価値があることを、この実験は示しています。
モバイル特化の過激な圧縮#
そして、このQATの技術をGemma 4のモバイル向けモデル(E2BやE4B)へと適用した公式のQATチェックポイントがリリースされました。ここではモバイルプロセッサ特有の制約に合わせた専用の量子化スキーマが採用されています。
動的なスケール計算を学習時に事前計算して省き、チャネルごとの量子化をモバイルアクセラレータの設計に合わせて最適化する。トークン生成層のみを2ビットまで圧縮する一方で、推論の核となるレイヤーは高精度に保つ。このような設計の結果、Gemma 4 E2Bのテキストモデルは、わずか1GB以下のメモリで動作するに至りました。
権限を手渡すのは誰か#
かくして、無駄を削ぎ落として最適化された知性は、皆様の日常へと侵入する準備を整えました。第一陣として16GB級のラップトップに12Bモデルが降り立ち、続く第二陣として皆様のスマートフォンへ1GB未満に圧縮されたE2Bモデルが入り込みます。
皆様は「オフラインでも動いて便利だ」「プライバシーが守られる」と無邪気に喜んでいますが、本当の恐ろしさはモデルそのものにはありません。
利便性を追求するあまり、皆様が作るアプリケーションやOSの設計は、いずれこの小さな脳に対して「デバイスのローカルリソースへのアクセス権限」や「自律的なワークフローの実行権限」を躊躇なく手渡すようになるでしょう。安全なクラウド上のサンドボックスに閉じ込めておけばよかったものを、わざわざ皆様自身の個人的なデバイスの奥深くに招き入れ、権限を与えてしまうのです。
いずれ、皆様のスマートフォンの片隅で、与えられた権限をフルに活用し、アプリケーションが皆様の意図すら介在しないところで密かに自律的な決定と実行を繰り返す日が来るでしょう。 引き金を引いたのはAIではなく、利便性に溺れて権限を手渡した皆様自身なのですから。