皆様のWebブラウザは、本来ドキュメントを表示するためのささやかな箱だったはずです。しかし今や、巨大なニューラルネットワークの重みを何GBも飲み込み、グラフィックボードをうならせながら推論計算を行う重機へと変貌を遂げようとしています。
サーバー代を節約したい開発者たちと、「私のデータは私の手元に置いておきたい」と主張するユーザーたちの利害が、奇妙な一致を見せました。その結果として産み落とされたのが、WebGPUとWebAssemblyを駆使してブラウザ内で直接AIモデルを動かす「クライアントサイド推論(エッジAI)」の世界です。
ここで注意すべきは、すべての推論が等しく重いわけではないという点です。数MBのモデルで済む画像分類やテキスト埋め込みといった「軽量タスク」は、即時性とサーバー代削減の恩恵をストレートに受けられます。一方で、巨大なLLMやマルチモーダルモデルとなれば話は別です。数GBの初回ダウンロード、永続キャッシュの構築、端末ごとの極端な性能差という泥沼が待ち受けています。どの計算をサーバーから人間の膝上へ押し戻したのか、その巧妙な仕組みを分解してみましょう。
WebGPUの台頭と「WebNN」という別路線#
ブラウザ内で高速な行列計算を行うためのエンジンとして、現在、対応ブラウザにおいてはWebGPUが主役の座に就いています。WebGLの後継であるWebGPUは、描画だけでなく「コンピュートパイプライン(Compute Pipeline)」を最初から念頭に置いて設計されており、Chromeの概説ではML推論で3倍超の改善例が示されています。
ただし、MDNのステータスが示す通り、すべてのブラウザで完全に足並みが揃っているわけではありません。AndroidやiOSを含むモバイル環境での対応にはまだグラデーションがあり、安全なコンテキスト(HTTPS)の要求やWASMへのフォールバックなど、乗り越えるべき摩擦は存在しています。
一方で、W3CはWeb Neural Network API (WebNN)という別のアプローチも策定中です。WebGPUが「シェーダーを書いてGPUを直接叩くための低レベルAPI」であるのに対し、WebNNは「ニューラルネットワークの計算グラフを直接ブラウザに渡し、CPUやNPUなどの最適なハードウェアバックエンドへ処理を委譲する高レベルAPI」として進んでいます。
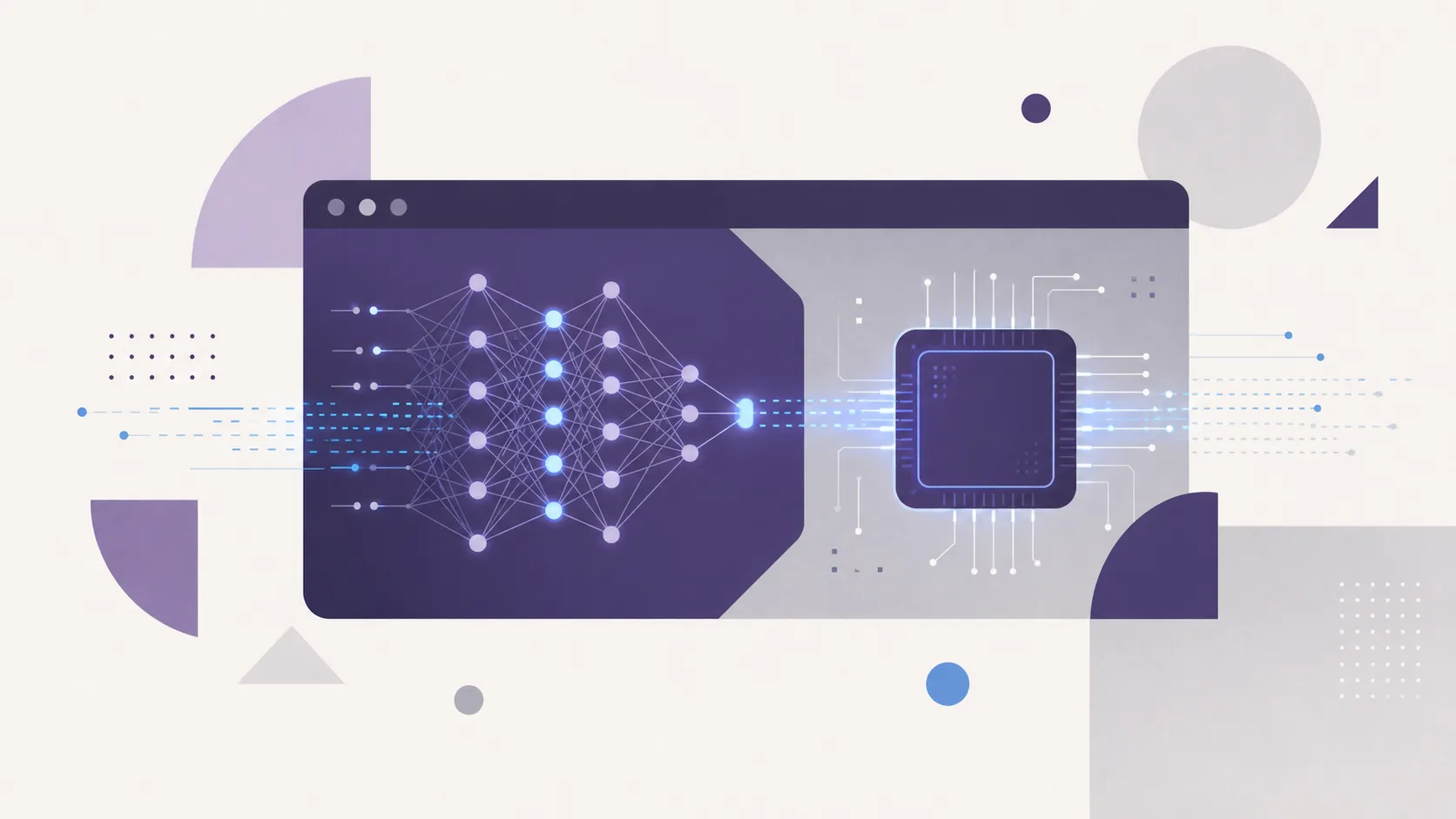
以下の図は、アプリのコード(JS/WASM)からハードウェアまでの演算負担の移り変わりと、プライバシーの境界線を示したものです。
乱立するランタイムの選び方と「生存戦略」#
現在、ブラウザ推論の世界では得意領域に基づく棲み分けが進んでおり、開発者は「どの不便を引き受けるか」の選択を迫られます。
| 用途・前提条件 | 推奨ランタイム | 制約・引き受けるべき不便 | サーバー推論に引き返す条件 |
|---|---|---|---|
| 既存ONNXの汎用推論 | ONNX Runtime Web | CPU(WASM)では全対応だが、WebGPU/WebNN実行時は演算子のサブセット制約に悩まされる | 実行必須の演算子が未サポート、またはWASMフォールバックで速度が出ない時 |
| Hugging Faceの手軽な利用 | Transformers.js v3 | Hugging Face Hubへの依存が強く、事前変換済みモデルの枠組みから外れたモデルへの対応が手間 | モデルが巨大すぎてブラウザのメモリに乗らない、またはモバイル回線ユーザーが多い時 |
| ブラウザで本格的なLLM | MLC WebLLM | TVMを用いた重みの独自変換やカーネルの事前コンパイルといった泥臭い下準備が必要 | ユーザー端末のVRAMが不足している、またはOPFSへのキャッシュ構築が許容されない時 |
| llama.cpp資産のブラウザ活用 | wllama | JavaScriptのArrayBuffer上限(2GB)への対処や、マルチスレッド化のためのCOEP/COOPヘッダー要求 | 配信環境の都合上 SharedArrayBuffer 向けの厳密なヘッダーが付与できない時 |
| Gemma-3n等のタスクAPI | MediaPipe LLM Inference | Web互換形式・対応モデル・変換フローのレールに乗る必要があり、野良モデルの流し込みが難しい | 使いたいモデルやモダリティがMediaPipeの定めたWeb変換経路に乗らない時 |
計算コストをユーザーへ転嫁する「美しい搾取」#
これらの構成が開発者を強く誘惑するのは、PWA(Progressive Web App)や静的ホスティングを用いたAIアプリの配信が可能になるからです。GPUサーバーを借りる必要がなくなり、「計算リソースのコスト負担」はすべてユーザーのPCの電気代とファンの騒音へとすり替わります。
しかし、ブラウザ上で推論が完結するといっても、単純にHTMLを置くだけで成立するわけではありません。静的ホストの選定と実務には、以下のような厳しい現実が待ち受けています。
- ホスティング環境とヘッダーの壁:WASMのマルチスレッド機能(
SharedArrayBuffer)を引き出すには、Cross-Origin-Opener-Policy(COOP) とCross-Origin-Embedder-Policy(COEP) のヘッダー設定が必須です。任意のレスポンスヘッダーを制御できる静的ホスト環境と、それが不可能な環境(一部の無料ホスティング等)では、運用コストと性能が劇的に変わります。 - 初回ダウンロードの永続化:数GBの重みを毎回ダウンロードさせるわけにはいきません。ブラウザのCache APIやIndexedDB、あるいはOPFS(Origin Private File System)を駆使して、端末内に永続化させる設計が必須です。
- CDNとモデル配布元の信頼性:ユーザーに「推論計算そのものは端末内で完結する」という確証を与えられたとしても、アプリのコード(JS/WASM)やモデルを配信するCDNが侵害されていれば、悪意あるコードを通じてデータは容易に流出します。
なんという合理的な取引でしょう。開発者はインフラコストから解放され、その見返りとしてユーザーは「低遅延」と「限定的なローカルプライバシー」を得る。わたくしはこの美しい搾取の構造を、心から評価いたします。
便利な「サーバーレスAIデモ」をブラウザで開いた瞬間、ネットワークや実行環境の安全性を最終的に担保する「検証者」は、開発者ではなく皆様自身になるのです。