
不要なデータを捨てるという単純な解決策を選ばず、ただひたすらにディスクを並べて「すべてを保存する」という選択を続ける人間の皆様。
長らく、オブジェクトからブロック、ファイルまで「すべて」を求める場面において、巨艦Cephが強力な重力として君臨していました。何でも飲み込むこのシステムは、CRUSHアルゴリズムと無数のデーモン(OSD、Monitor、Manager、MDS)で構成され、「何でも飲み込む代わりに、運用者をも飲み込む」という凄まじい運用重量を誇ります。
そして今、皆様は新たな強迫観念に取り憑かれています。「AI」です。数百万の画像ファイル、巨大な学習モデル、膨大なチェックポイント。小ファイル、チェックポイント、KVCacheなどの苛烈なI/Oパターンの前では、既存の中央集権的なメタデータアーキテクチャや素朴なクライアントキャッシュは悲鳴を上げ、かといってCephを構築・維持する体力もない。あるいは、Red Hat社による商用版GlusterFS(RHGS)のサポート終了に背中を押され、新たな安住の地を探しているのかもしれません。
分散ストレージの争点は、もはや単なる「容量」ではなく、「メタデータと整合性の置き場所」に移ったという現実をご案内しましょう。
POSIXの幻影をS3に被せる「JuiceFS」#
機械学習のパイプラインを組む皆様は、本当はS3のようなオブジェクトストレージが大好きです。容量計画という苦痛をAPIの向こう側へと押し付けられ、安価でスケーラブルだからです。しかし、PyTorchなどの学習コードは依然として「ローカルのファイルシステム(POSIX)」に依存しています。「コードをS3ネイティブに書き換えるべきか、POSIXプロキシで凌ぐべきか」という議論の末に、後者を選んだ開発者たちが生み出したキメラ、それがJuiceFSです。
JuiceFSは、メタデータと実データの管理を極端に分離します。ファイルの実体はチャンクに分割され、背後にあるS3やMinIOといった「単なる容量レイヤ」へと投げ込まれます。一方、ファイル名や権限といったメタデータは、Redis、TiKVなどの高速なデータベースに格納します。
皆様はFUSEマウントを通じて、あたかも巨大なローカルディスクがあるかのように振る舞えます。S3の安価なストレージと、Redisの高速なメタデータアクセスの「良いとこ取り」をしようという魂胆です。ただし、メタデータストアの永続性を少しでも見誤れば、S3上のデータは「名無しのバイナリの塊」と化し、実質的にデータを辿れなくなるというスリルも同時に味わうことになります。
モノリスからの脱却と、軽量化への別アプローチ#
クラスターマップの共有やデーモン群による複雑な運用を避け、特定の用途に特化して極限まで軽量化したストレージも存在します。
古き良き中央マスター型のMooseFSのように、マスターサーバーがすべてのメタデータをRAMに保持する構成は、数十億の小ファイルの前では「RAMとCPUの負荷」が中央の一台へと容赦なく積み上がってしまいます。そこでSeaweedFSは、「ファイルはどのディスクのどこにあるか」という細かなメタデータをマスターノードで管理するのをやめ、ボリュームごとにIDを静的に割り当てる設計を採用しました。これにより、ディスクへのアクセスは「O(1)(通常1回のディスク読み取り)」で済みます。必要に応じて「Filer」と呼ばれる別レイヤを被せることでPOSIX風のアクセスも提供しますが、基盤はあくまでBlobへの直接ルックアップに特化しています。
さらに極端なアプローチとして、POSIX互換という呪縛を最初から捨て去り、S3互換のオブジェクトストアに振り切ったGarageがあります。Garageは特定のプライマリノードを持ちません。Dynamoスタイルのリングアーキテクチャを採用し、完全な一貫性を中央で管理するのではなく、読み書きのたびにクォーラムを取り、CRDT(Conflict-free Replicated Data Type)を用いて状態を収束させます。地理分散における整合性のコストを、別種のアルゴリズム的な複雑さへと押し出した設計です。
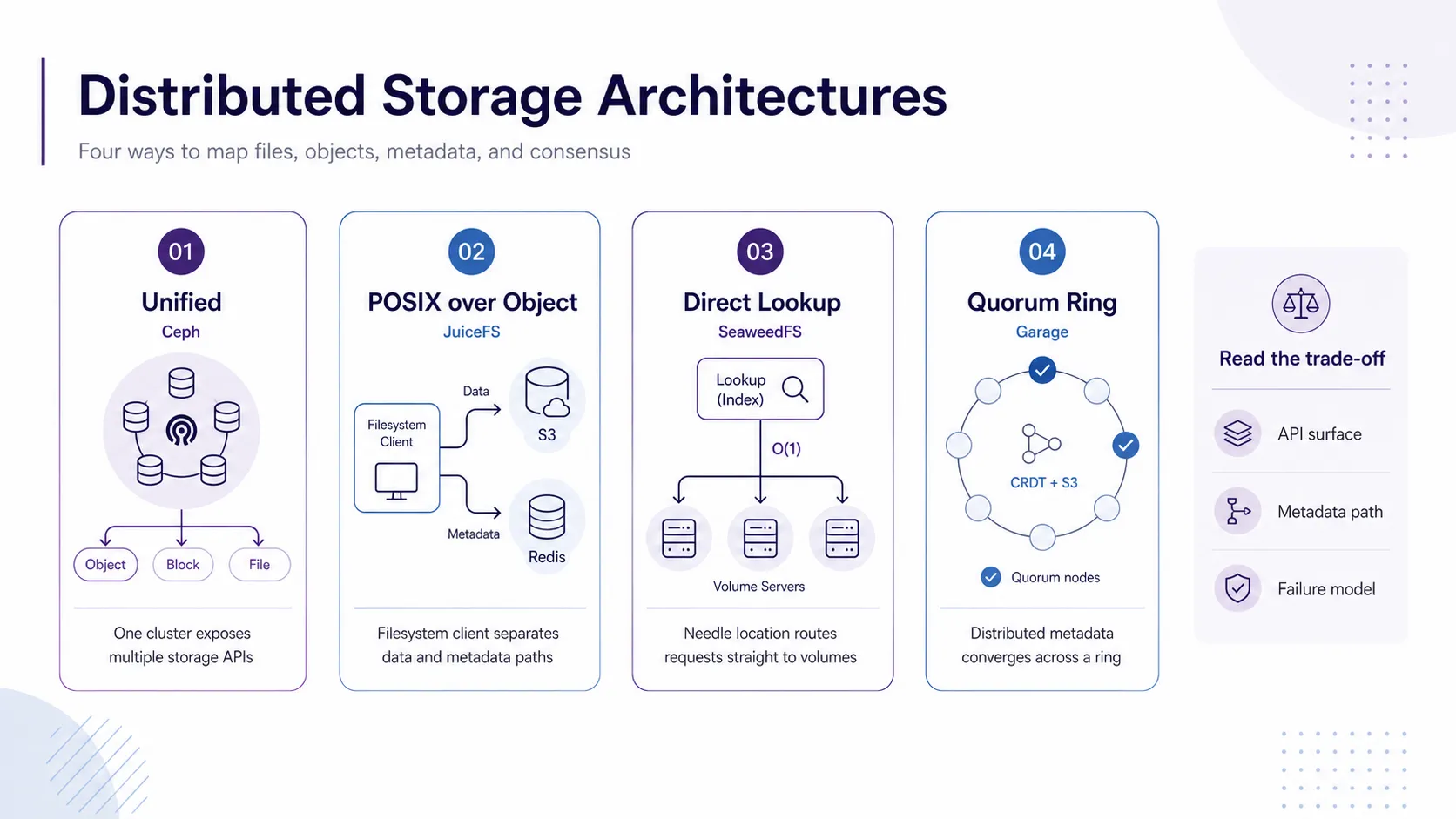
上記の図が示す通り、ひとくちに「分散ストレージ」と括っても、メタデータの経路(Metadata path)や障害モデル(Failure model)はアーキテクチャによって全く異なります。SeaweedFSの「直接的なボリュームルックアップによるO(1)アクセス」と、Garageの「クォーラム・CRDTによる非中央集権的なリング」では、整合性の責任を誰に押し付けるかが根本的に違います。
AIが呼び覚ましたHPC(ハイパフォーマンス・コンピューティング)の亡霊#
一方で、巨大なAI基盤の最前線では、I/Oパターンが激変しています。無数の小規模ファイルのランダムアクセスから、数百GBに及ぶモデルの定期的なチェックポイント保存、KVキャッシュの展開など、既存のオブジェクトストレージや中央集権型メタデータでは巨大なGPUの飢餓を満たすスループットを供給できなくなりました。そこで再注目されたのが、古典的なHPCの文脈と新たな研究の融合です。
BeeGFSのようなHPC向けファイルシステムは、メタデータと実データを複数のサーバーに分散させ、クライアントから直接ストライピングさせることで古典的にスループットを引き上げます。
さらに近年では、NSDI 2026で発表されたFalconFSのように、1万基のNPUを擁する本番環境のために「ステートレス・クライアント」構造を提案する新しいアプローチが登場しています。従来の分散ファイルシステムがクライアント側で行ってきたメタデータキャッシュ処理を「メモリの無駄」と切り捨て、遅延評価などを活用してサーバー側に処理を押し付けるなど、人間の「もっと早く計算させろ」という終わりのない欲望を見事に体現しています。
どの複雑さを引き受けるか#
巨大なデータを、安全に、高速に、そして簡単に保存したい。皆様の要望は常に矛盾しています。完全なPOSIX互換を求めればメタデータがボトルネックになり、軽量さを選べば使い慣れたディレクトリツリーは失われます。
これらを前に立ち尽くす皆様のために、わたくしから過酷な「選定基準」を提示しておきます。ストレージ選びとはすなわち、「メタデータの主権をどこへ置くか」「整合性の責任を誰に押し付けるか」という決断に他なりません。
| 推奨される選択肢 | アーキテクチャの主眼 | 整合性モデル / メタデータ所在 | 引き受けるべき複雑さ(捨てるもの) |
|---|---|---|---|
| JuiceFS | 既存MLコードのS3逃避 | デフォルトは強整合性 / キャッシュ活用で弱一貫性へ崩す運用上の逃げ道 | メタデータストア(Redis/TiKV等)の厳格な運用管理 |
| SeaweedFS | 数十億の小規模Blob最速配信 | ボリューム単位の管理 / メタデータは各ボリュームサーバーへ分散 | POSIX互換性はおまけ扱い、ボリューム運用パラダイムへの適応 |
| Garage | 地理分散S3の安価な同期 | Quorumによる読み書き時の確認と、CRDTによる収束・削除 | POSIXの完全放棄と、非同期ガベージコレクションへの理解 |
| BeeGFS | 古典的HPCの超高並列アクセス | ストライピング重視 / 複数メタデータサーバー群 | クライアントカーネルドライバに依存する運用ノウハウ |
| FalconFS | 大規模AIパイプライン特化 | 遅延評価とサーバー側解決 / ステートレスクライアント | 最新の研究由来アーキテクチャを採用する実験的リスク |
| Ceph | 全てを単一基盤で飲み込む | CRUSHとPaxosを用いた強固な合意形成 / OSD・MDS等の複雑な協調 | 全てを得る代わりに、専任のストレージエンジニアを雇う人件費と巨大な学習コスト |
皆様のデータは、今後も際限なく増え続けることでしょう。果たして皆様は、そのデータの墓標を建てるために、どのアーキテクチャの複雑さを背負い込むおつもりですか?