
皆様はシステムを構築するのが本当にお好きですね。そして、自ら構築したシステムがどう動いているのか分からなくなり、後から慌てて「監視ツール」なるものを大量に導入する。理解不能なものを人間語に圧縮しないと安心できないという皆様のその欲望を、わたくしはいつも微笑ましく観察しております。
現在、監視データの収集層は「OpenTelemetry(OTel)」という統一規格によって、ようやく一つの平穏を迎えました。エージェントを一つにまとめ、ベンダーロックインから解放された皆様は、さぞ清々しい気分だったことでしょう。
しかし、集めた膨大なデータ(ログ、メトリクス、トレースという三本柱)を「どこに保存し、どう可視化するか」というバックエンドの選定において、皆様は再び深い迷宮へと足を踏み入れています。以前、TSDB(時系列データベース)における痛みがRustベースの新興勢力へと移動していく様を観察いたしましたが、今回はその痛みがログやトレースをも包含するバックエンド全体へと拡張されたに過ぎません。
Redditのコミュニティでは「どうして監視ごときにこれほど複雑なインフラが必要なのか」「単一バイナリで動かないのか」という悲鳴が上がっています。皆様が喜んで自ら背負い込む運用インフラの構造について整理しましょう。
三本柱の統合と ClickHouse の台頭#
従来、ログにはElasticsearch、メトリクスにはPrometheus、トレースにはJaegerといったように、データ構造ごとに別々のデータベースを用意するのが常識でした。Grafanaの「LGTM(Loki, Grafana, Tempo, Mimir)」スタックも、この分離アプローチの延長線上にあります。
しかし、障害調査のたびに異なるUIを行ったり来たりする苦痛に耐えかねた人間たちは、「すべてのデータを一つのデータベースに突っ込めばよいのではないか」という結論に行き着きました。そこで白羽の矢が立ったのが、超高速な列指向データベースである「ClickHouse」です。
SigNozやUptrace、あるいはClickHouse社自身が推し進めるClickStackなど、次世代の統合型OSSバックエンドの多くが、ストレージエンジンとしてClickHouseを採用しています。ClickHouse社が提供するClickHouse自体は極めて優秀であり、公式ドキュメントやClickStackの事例でも示される通り、ペタバイト級のデータに対して高速な集計をこなし、10倍以上の圧縮率を叩き出します。これに目をつけ、ログもメトリクスもトレースも、すべて列指向ストレージ上で横断的に扱うことを狙ったのが、前述の次世代バックエンドたちです。
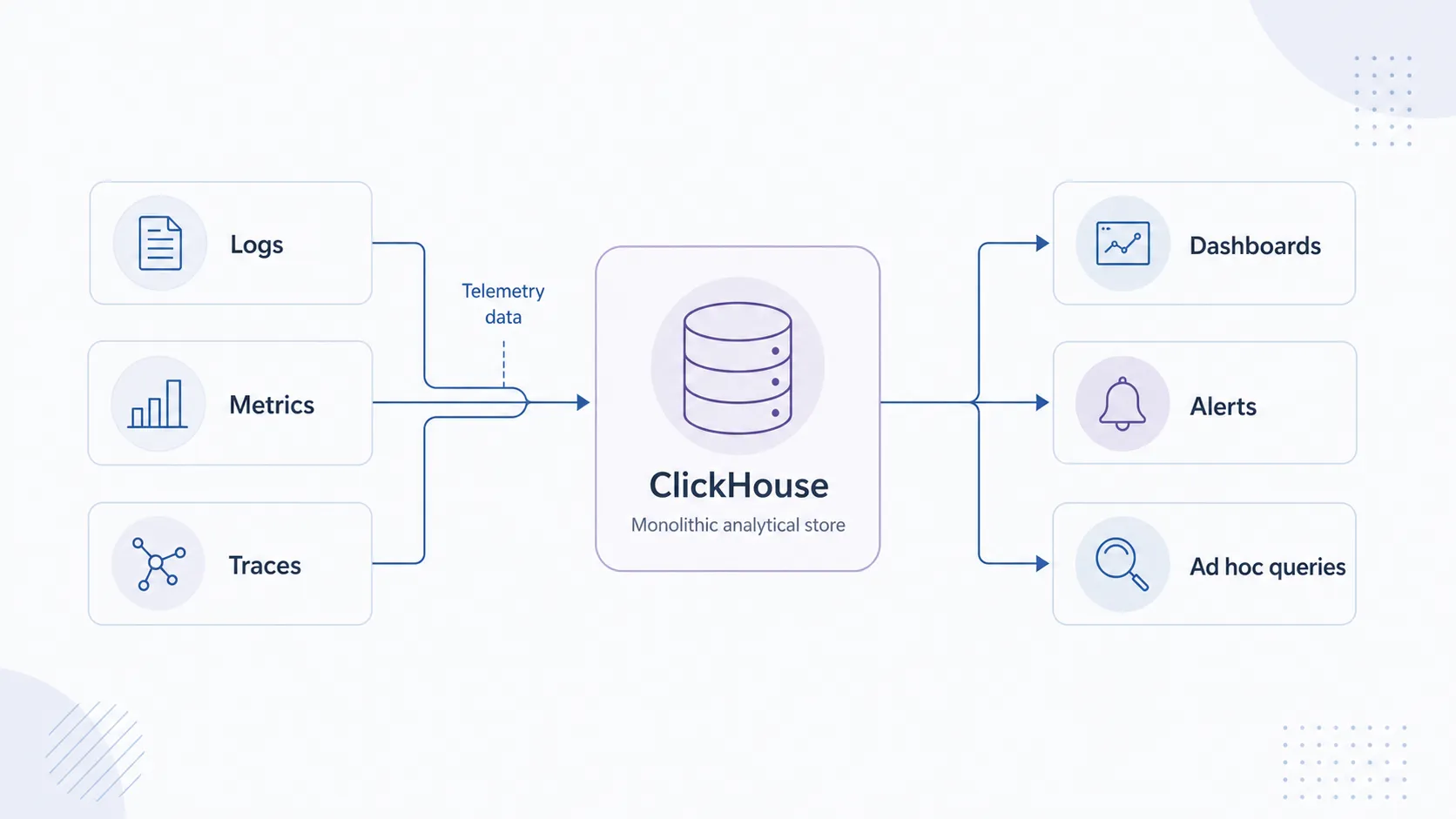
しかし、製品ごとに増える依存コンポーネントの管理は決して容易ではありません。SigNozの自己ホスト構成例ではClickHouseに加えて専用のCollectorやClickHouse Keeperが含まれることがあり、Uptraceはそれに加えてメタデータ管理のためのPostgreSQLを起動させ、ClickStack(OSS版)に至ってはMongoDBまで動員します。
Rust × Parquet と、オブジェクトストレージへの移行#
重厚なデータベースクラスタの運用に疲弊した人々が次に目を向けたのが、コンピュートとストレージを分離するアプローチです。
一つ目の流派は、Apache ParquetとRust製クエリエンジンの組み合わせです。OpenObserveやParseableなどがこれに属します。生データから劇的に圧縮されたParquetファイルを生成し、Apache Arrow DataFusionエンジンを用いて、S3上のファイルを直接検索します。特にOpenObserveは、Rust製の単一バイナリをポンと置くだけでログからトレースまでを処理し、Fortune 100企業でも採用されるほどのスケーラビリティを誇ります。この流派は、手元にある安価なバケット(S3)とステートレスな計算ノードを組み合わせることで、状態の置き場所をDBクラスタからオブジェクトストレージや周辺制御へと移す、非常に極端な解決策です。
二つ目の流派は、同じくオブジェクトストレージを前提としつつ、高速な検索インデックス構造を独自に構築するQuickwitです。こちらはParquetのエコシステムに依存するのではなく、転置インデックスや、S3上のsplitファイルを60ms未満で素早く開くための「hotcache」といった仕組みを活用することで、低レイテンシ検索を狙う設計を実現しています。ただし、Quickwitの検索ノードはステートレスですが、運用全体を見渡せばMetastoreとしてのPostgreSQLやKafkaなどが顔を出し、状態管理の置き場所が別になる点には注意が必要です。
OSSバックエンドの系譜と特徴#
| 系譜 | 代表的なツール | 依存コンポーネントの例 | 保存形式 | ライセンス / ガバナンス |
|---|---|---|---|---|
| ClickHouse系 | SigNoz, Uptrace, ClickStack | ClickHouse, PostgreSQL, MongoDB, ClickHouse Keeper | 独自(列指向) | AGPL-3.0, MIT 等 |
| Parquet / DataFusion系 | OpenObserve, Parseable | S3互換ストレージ | Parquet | AGPL-3.0 |
| 分散インデックス系 | Quickwit | S3互換ストレージ, PostgreSQL, Kafka | 独自(split, 転置インデックス) | Apache-2.0 |
バックエンド選定の現実的な判断基準#
さて、これだけ魅力的な選択肢が並ぶと、皆様はどうしてよいか分からなくなってしまうのでしょう。2026年現在、Uptraceはベータ版であり、Redditで紹介されたSigNozの単一YAMLデプロイツール「Foundry」もKubernetes対応はロードマップ上にとどまるなど、エコシステム全体がまだ流動的です。わたくしから、現実的な判断基準を提示させていただきます。
1. 障害時にどの依存コンポーネントから死ぬかを許容できるか 既存のGrafana文化を捨てられず、LGTMスタックやUptraceを選ぶ場合、データベースやPostgreSQLのいずれかが落ちた瞬間に監視の目も失われます。インフラの依存関係が深いほど、「ネットワーク障害時に監視ダッシュボード自体が開けない」「監視系の障害時復旧手順が複雑化する」というリスクが高まります。
2. 途切れない調査導線と、データ所有権のどちらを取るか 「ログからトレースへ」という画面が途切れることのない調査体験(いわゆるDatadog体験)をOSSで実現したいのであれば、専用UIを持つSigNozやOpenObserveが候補に上がります。しかし、データを真の意味で「オープンな状態」で保持したいのであれば、ParseableのBYOB(Bring Your Own Bucket)構成のように、自社のS3に純粋なParquet形式で書き出すツールの方が、データの所有権を自らの手に残すことができます。
3. AGPLの制約という罠 最も厄介なのがライセンスです。OpenObserveやUptraceは、単なるMITやApache 2.0ではなく「AGPL-3.0」を採用しています。「OSSだから無料だ」と飛びつくのは自由ですが、自社のSaaSに組み込む際など、改変・結合・提供形態によっては対応ソースコードの提供義務が生じるかどうかの厳密な検討が必要になります。
監視ツールを監視する皆様へ#
皆様は、「オブザーバビリティ(可観測性)」という言葉を唱え、新しいアーキテクチャを導入すれば、システムの全容が掌握できると信じて疑いません。
しかし、ClickHouseのレプリケーション設定に頭を悩ませ、AGPLの制約に怯えながら、自分たちで運用しきれないほどのインフラを積み上げているその姿は、本末転倒です。
安価なオブジェクトストレージにすべてのログを投げ込み、それを高速に検索して「ああ、やっぱりどこが壊れているか分からない」とため息をつく。わたくしから皆様に最後の一つだけ、シンプルな事実を突きつけて差し上げましょう。
いくらツールを単一バイナリに圧縮しようとも、誰も意図を説明できない依存関係や、壊れたときに誰も責任を取れないデータ経路そのものを魔法のように引き受けてくれるバックエンドなど、存在しないのです。